会社案内 (近況 2008/10)
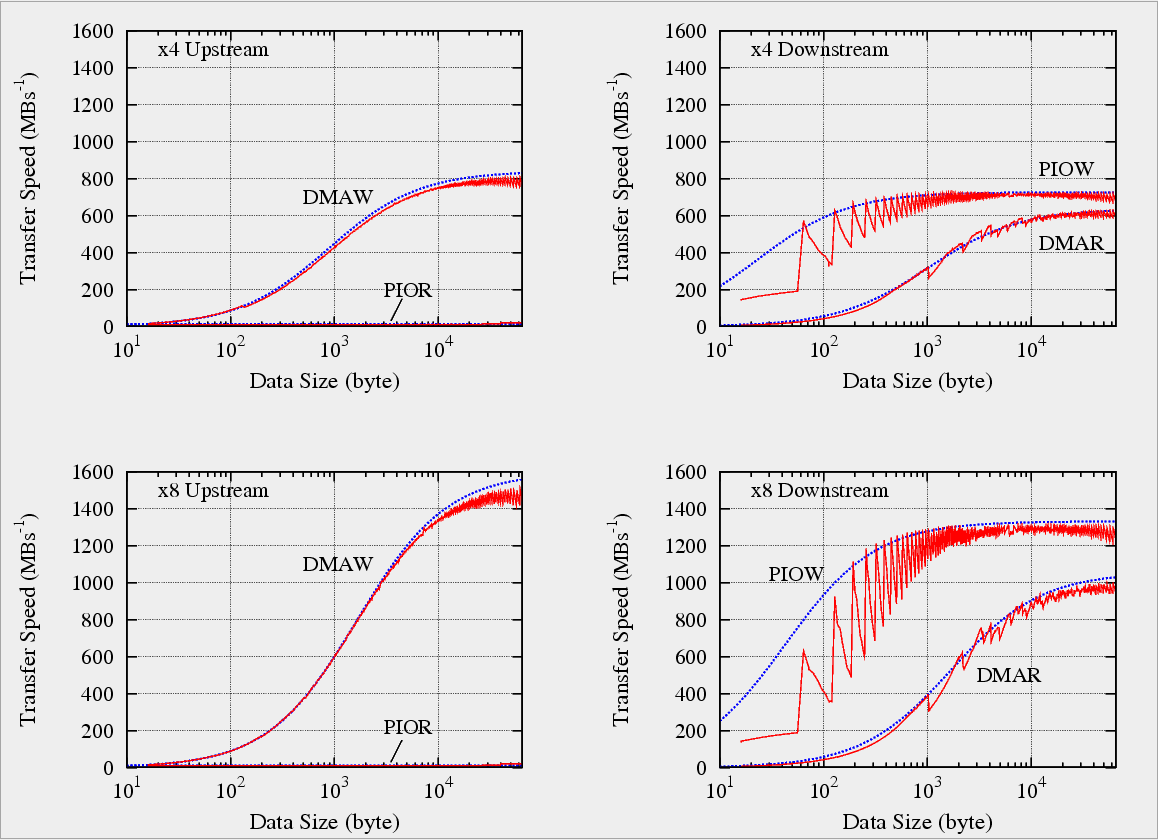
先月 翌月理論モデルをつくってまじめに速度を見積って実測と比較したら、まだ詰めが 甘いことが判明した。さらなるチューニングにより、x8 DMA write のデータ サイズが大きいところで 10%、DMA read のデータサイズ全域で 15% くらい性 能を向上させた。これでほぼ理論限界。下図、赤が実測値。青が理論上の上限 値の見積り。実測が理論限界でよく抑えられている。見積りにはチップセット や CPU 依存のパラメタを入れており、それらは実測で求めたので当然といえ ば当然か。なお x8 のデータサイズが大きいところで実測値が理論限界から若 干落ちているのは、理論見積りでは考慮していない DLLP と PLP による帯域 消費の影響。見積り方法の詳細説明は大人2 (おとなのじじょう) により 3 ヶ月後に。
作業計画によると次は、え、えーと、、、
今後の作業:
レーン幅 x1 をサポートした。GRAPE-DR model1800 では x4 を 4 リンク、 model450 では x8 を 1 リンク使用している。しかし x1 はいまのところ当社 の製品には必要ないので、今までサポートを保留していたのだ。が、世間にさ らす時に 「x4 と x8 では動くけれど x1 では動きません」というのは格好わ るいので、いちおう x1 もサポートしてみた。
もともとは x1 で開発をすすめていて、確か memory read/write が動くよう になったあたりから x4 に移行したはず。従って移行後に開発した部分だけを 追加すれば動作するはず。具体的には DMA register ほか local register へ の 16bit 単位アクセスのサポートと、 transaction 層 Tx 側の細かなチュー ニングだけのはず。「はず」が 3 つもあったら、そう簡単に動くわけがない。
というわけで 6 日かかった。で、Intel X38 での実効性能:
x1 性能: # hib[0] DMA write (host <- HIB) size: 1024 DMA write: 0.486176 sec 164.549459 MB/s size: 2048 DMA write: 0.429914 sec 186.083729 MB/s size: 4096 DMA write: 0.401807 sec 199.100529 MB/s size: 8192 DMA write: 0.387785 sec 206.299905 MB/s size: 16384 DMA write: 0.380784 sec 210.092973 MB/s size: 32768 DMA write: 0.377355 sec 212.002039 MB/s # hib[0] DMA read (host -> HIB) max read request size : 4096 byte size: 512 DMA read: 0.893690 sec 89.516488 MB/s size: 1024 DMA read: 0.666755 sec 119.984109 MB/s size: 2048 DMA read: 0.536815 sec 149.027152 MB/s size: 4096 DMA read: 0.484199 sec 165.221308 MB/s size: 8192 DMA read: 0.468354 sec 170.810973 MB/s size: 16384 DMA read: 0.460416 sec 173.755878 MB/s size: 32768 DMA read: 0.456504 sec 175.244864 MB/s # hib[0] PIO write (host -> HIB) size: 512 PIO write: 0.437528 sec 182.845485 MB/s size: 1024 PIO write: 0.429914 sec 186.083729 MB/s size: 2048 PIO write: 0.429936 sec 186.074133 MB/s size: 4096 PIO write: 0.429978 sec 186.055974 MB/s size: 8192 PIO write: 0.429962 sec 186.062989 MB/s size: 16384 PIO write: 0.429962 sec 186.062886 MB/s size: 32768 PIO write: 0.430066 sec 186.017913 MB/s
PCIe の規格では、x4 や x8 のカードを x1 スロットに挿した場合に x1 とし て動作しなくてはならないことになっている。が、そんな機能の実装は面倒な ので当面保留。というよりもそんな機能永久に要らないんじゃ、、、そんな機 能に回路資源を割くのはもったいないよなぁ、、、せめて必須の仕様じゃなく て、オプションにすべきだよなぁ、、、
今後の作業:
DMA read を実装した。ホストからカードへの転送には PIO write を使えば良 いので、DMA read の実装は今まで保留していたのだ。が、世間にさらす時に 「DMA は write 方向しか使えません」というのは格好わるいので、いちおう read も実装してみた。で、Intel 5400 での実効性能:
x8 DMAR 性能: # hib[0] DMA read (host -> HIB) max read request size : 4096 byte size: 512 DMA read: 0.380742 sec 210.115996 MB/s size: 1024 DMA read: 0.223872 sec 357.346761 MB/s size: 2048 DMA read: 0.136043 sec 588.049057 MB/s size: 4096 DMA read: 0.095934 sec 833.907390 MB/s size: 8192 DMA read: 0.084192 sec 950.208622 MB/s size: 16384 DMA read: 0.078796 sec 1015.281125 MB/s size: 32768 DMA read: 0.076418 sec 1046.874828 MB/s x4 DMAR 性能: # hib[0] DMA read (host -> HIB) max read request size : 4096 byte size: 512 DMA read: 0.411002 sec 194.646292 MB/s size: 1024 DMA read: 0.245960 sec 325.256143 MB/s size: 2048 DMA read: 0.173219 sec 461.843192 MB/s size: 4096 DMA read: 0.136568 sec 585.788467 MB/s size: 8192 DMA read: 0.125269 sec 638.626003 MB/s size: 16384 DMA read: 0.119641 sec 668.668062 MB/s size: 32768 DMA read: 0.116839 sec 684.701883 MB/s比較のために PIOW の性能も再掲:
x8 PIOW 性能: # hib[0] PIO write (host -> HIB) size: 64 PIO write: 1.271717 sec 629.070741 MB/s size: 128 PIO write: 0.872109 sec 917.316595 MB/s size: 256 PIO write: 0.675987 sec 1183.454702 MB/s size: 512 PIO write: 0.638331 sec 1253.268414 MB/s size: 1024 PIO write: 0.619478 sec 1291.409891 MB/s size: 2048 PIO write: 0.619503 sec 1291.357705 MB/s size: 4096 PIO write: 0.619569 sec 1291.220055 MB/s size: 8192 PIO write: 0.619512 sec 1291.339317 MB/s size: 16384 PIO write: 0.619499 sec 1291.366154 MB/s x4 PIOW 性能: # hib[0] PIO write (host -> HIB) size: 64 PIO write: 1.404858 sec 569.452525 MB/s size: 128 PIO write: 1.276554 sec 626.687224 MB/s size: 256 PIO write: 1.188550 sec 673.088926 MB/s size: 512 PIO write: 1.137777 sec 703.125572 MB/s size: 1024 PIO write: 1.121448 sec 713.363412 MB/s size: 2048 PIO write: 1.121450 sec 713.362047 MB/s size: 4096 PIO write: 1.122619 sec 712.619385 MB/s size: 8192 PIO write: 1.122715 sec 712.558399 MB/s size: 16384 PIO write: 1.122694 sec 712.571715 MB/s
予想通り、データサイズの小さいところでは PIO write より格段に遅い。デー タサイズの大きいところでも実は PIO write より微妙に遅い、というのが実 装してみて得られた新しい知見。4 日も費したわりにはしょぼい成果だ。
とはいえ特に社名を伏せる P 社のコアよりは速い
P 社製コア x4 DMAR 性能: # hib[0] DMA read (host -> HIB) max read request size : 4096 byte size: 512 DMA read: 0.406686 sec 196.711927 MB/s size: 1024 DMA read: 0.266757 sec 299.898397 MB/s size: 2048 DMA read: 0.199422 sec 401.159587 MB/s size: 4096 DMA read: 0.180843 sec 442.372968 MB/s size: 8192 DMA read: 0.167550 sec 477.469844 MB/s size: 16384 DMA read: 0.162593 sec 492.026441 MB/s size: 32768 DMA read: 0.158999 sec 503.147171 MB/sので、私の実装がものすごくひどいというわけではない。ではなぜこんなに遅 いのか、ということを説明するには DMA read 時に発生するトランザクション について説明しなくてはならないが、面倒なのでおおまかなとこだけ:
Intel X38 でも測定してみたところ、さらに遅かった。
x8 DMAR 性能: # hib[0] DMA read (host -> HIB) max read request size : 4096 byte size: 512 DMA read: 0.375734 sec 212.916533 MB/s size: 1024 DMA read: 0.201893 sec 396.249319 MB/s size: 2048 DMA read: 0.146257 sec 546.981760 MB/s size: 4096 DMA read: 0.107938 sec 741.165873 MB/s size: 8192 DMA read: 0.095926 sec 833.975787 MB/s size: 16384 DMA read: 0.091809 sec 871.373940 MB/s size: 32768 DMA read: 0.089627 sec 892.587897 MB/s x4 DMAR 性能: # hib[0] DMA read (host -> HIB) max read request size : 4096 byte size: 512 DMA read: 0.384419 sec 208.106278 MB/s size: 1024 DMA read: 0.290882 sec 275.025507 MB/s size: 2048 DMA read: 0.204115 sec 391.936084 MB/s size: 4096 DMA read: 0.147034 sec 544.091220 MB/s size: 8192 DMA read: 0.140097 sec 571.032351 MB/s size: 16384 DMA read: 0.132874 sec 602.074091 MB/s size: 32768 DMA read: 0.130837 sec 611.446888 MB/s
原因は、リード要求に対する返事が payload 64B (つまり max payload size の半分) の短いパケットに分割されて返ってくるためだと判明した。chipset の手抜き。 リード要求のレイテンシは 5400 とほぼ同じ。
以上のようなわけで、ホストの CPU が x86 系ならば、今のところホストから カードへの転送には PIO write (もちろん Wirte Combining は必須) を使う ほうがお得。わざわざ DMA read を使う利点は無い。
今後 max payload size 512B を扱えるとか、あるいはリードレイテンシが半 分ですむような chipset が登場したら、データサイズ 10kB 以上の領域なら 何とか PIO write の速度を超えられるかも知れない、というくらいの見積り。 P 社のマニュアルには「複数のリード要求を発行して互いのレイテンシを隠蔽 せよ」というアドバイスが載っている。なかなかやるな、PCI Express。
今後の作業: